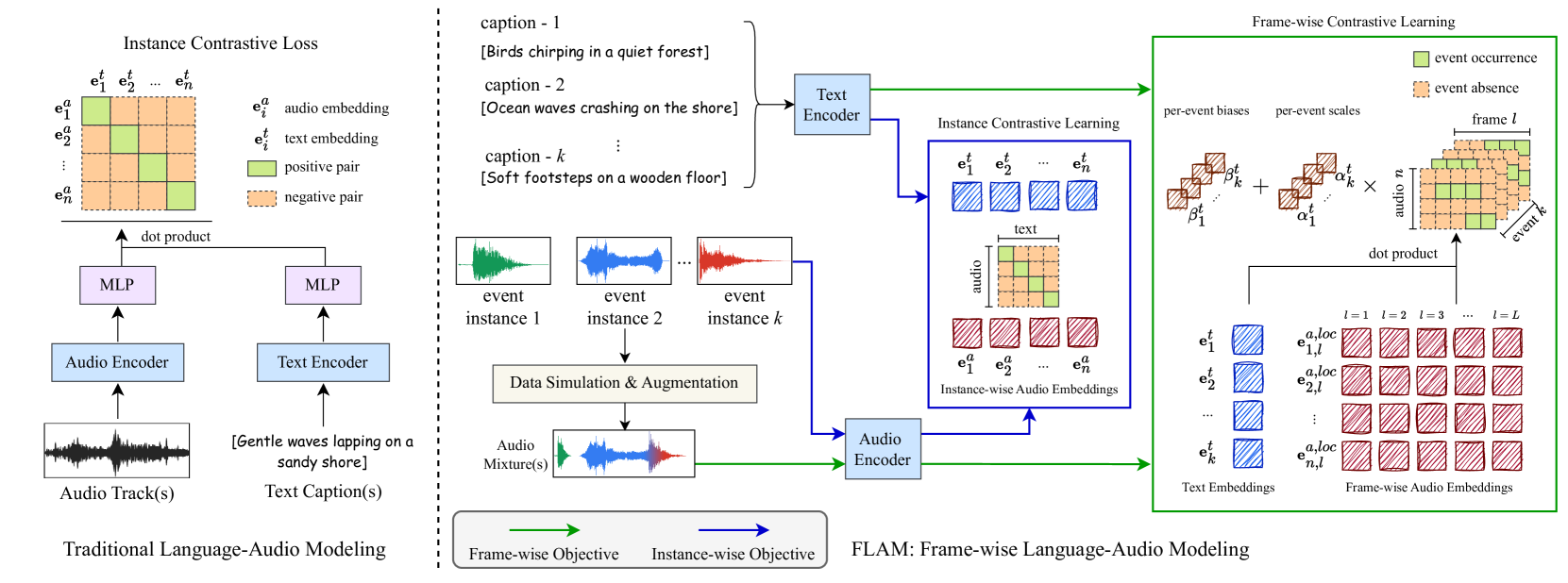
FLAM Zero-Shot Detection Results on Real-world Examples
We present FLAM's zero-shot, open vocabulary sound event detection on real-world audio examples that are not seen during training. We also include detection results of events that are not present in the examples in red. The title of each video links to the corresponding YouTube video.
Sound Event Detection Results
ASFX-SED Dataset (zero-shot, open-vocabulary)
example 1
example 2
example 3
example 4
Synthetic Held-out Dataset (zero-shot, open-vocabulary)
example 1
example 2
example 3
example 4
Audioset-Strong Dataset
example 1
example 2
example 3
example 4