Response to Reviewer bqpP
Experiment Details
This page includes the results of additional ablation experiments of FLAM. Two configurations of FLAM were used for the experiments:
- FLAM - no global loss: The FLAM model trained without the global loss, only with the local loss.
- FLAM - L=128: A FLAM model with a different audio encoder that outputs 128 frames for 10 seconds of input.
Experiment Results
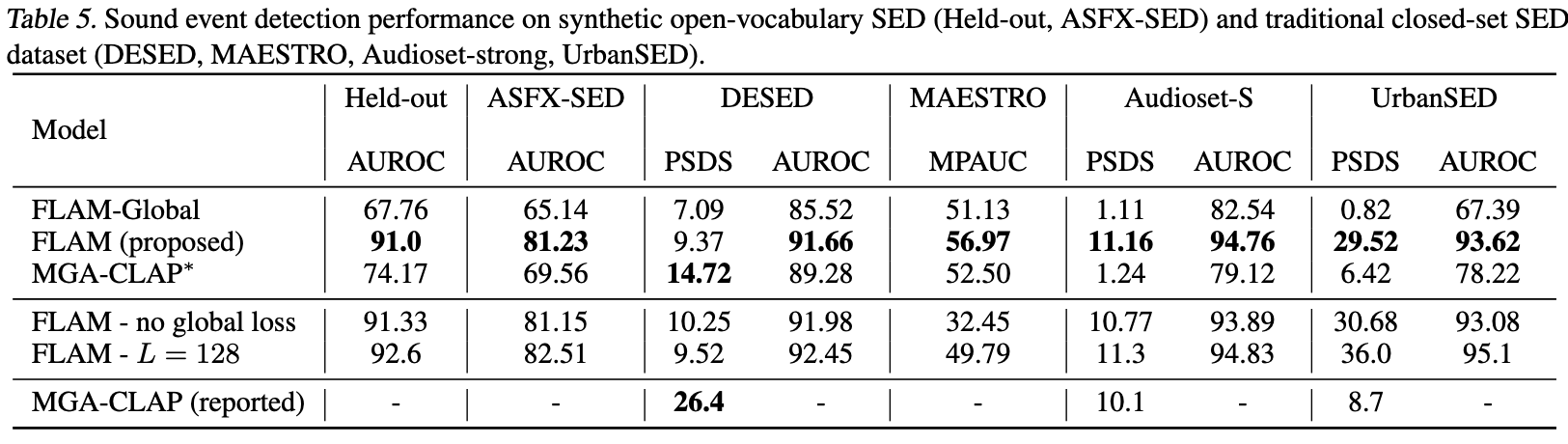
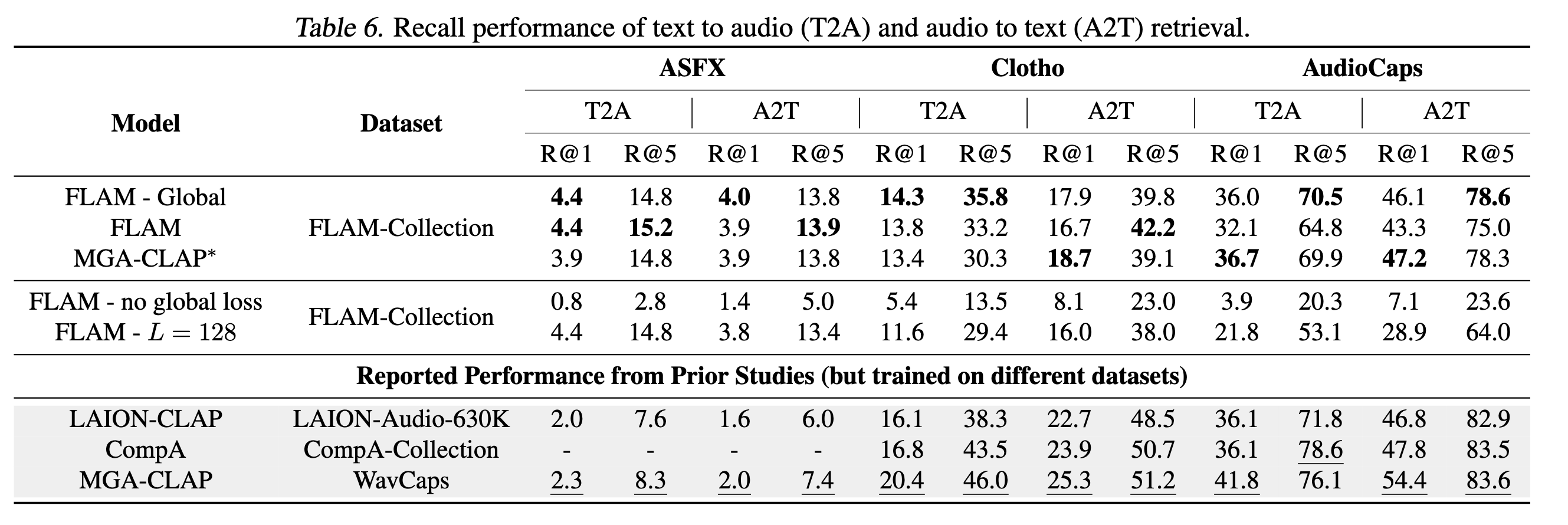
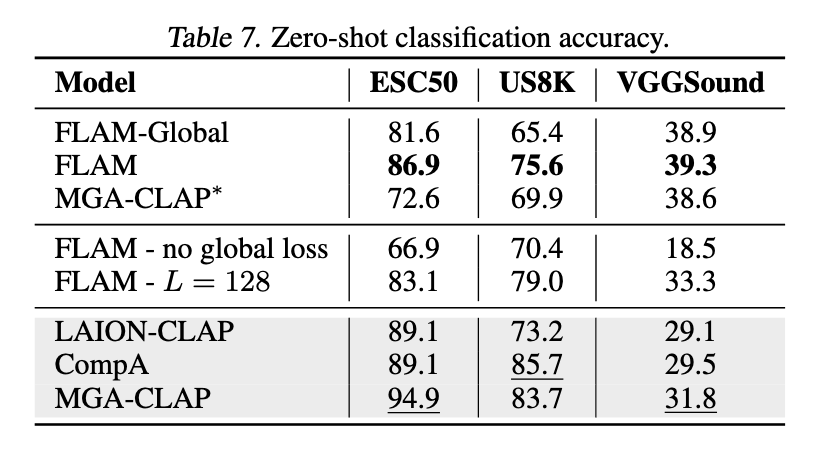
The results of the experiments are shown in the following figures. Removing the global loss, although marginally improves the SED performance, significantly reduces the retrieval performance and zero-shot classification performance. Using the audio encoder with larger output resolution results in similar trade-off, where the SED performance is marginally improved but the retrieval and zero-shot classification performance are reduced. Overall, we think that the original FLAM model achieves a good trade-off between the SED, retrieval, and zero-shot classification performance, with sufficient temporal resolution.
Tables
About the impact and intuition about logit scale
Intuitively, a smaller logit scale increases the cosine distance between negative frame and text embeddings for the same loss effect. This helps the model capture finer distinctions in cosine similarity. Experimentally, we clarify our findings in Figure 3: Performance in F1 drops more when we remove the per-text bias (but retain the per-text scale), than when we remove the per-text scale (but retain the per-text bias). So per-text logit bias plays a more significant role in performance than per-text logit scale, which is still beneficial.
We train the text-dependent logit scale $\alpha^t$ in similar manner where another MLP appended to text feature extractor, giving $\alpha^t(y) = \mathrm{MLP}^\alpha(E^t(y))$. Different in per-text bias, we update $\mathrm{MLP}^\alpha$ via $\mathcal{L}_{\mathrm{SED}}$ in Eq. 4.
Impact Statement
This work introduces FLAM, a model for frame-wise audio-language alignment to improve sound event detection using natural language queries. Our goal is to advance the field of multimodal learning by enabling fine-grained and interpretable audio understanding. FLAM may benefit applications such as content indexing, accessibility, and multimedia retrieval. While we do not foresee significant ethical risks, we encourage responsible use of the model in real-world scenarios.