Response to Reviewer GGdQ
Experiment Details
This page includes the results of additional ablation experiments of FLAM. Two configurations of FLAM were used for the experiments:
- FLAM - 256 batch size: The FLAM model trained with a batch size of 256.
- FLAM - 128 batch size: The FLAM model trained with a batch size of 128.
- FLAM - no sigmoid loss: The FLAM model trained without the sigmoid in SED objective (see equation below).
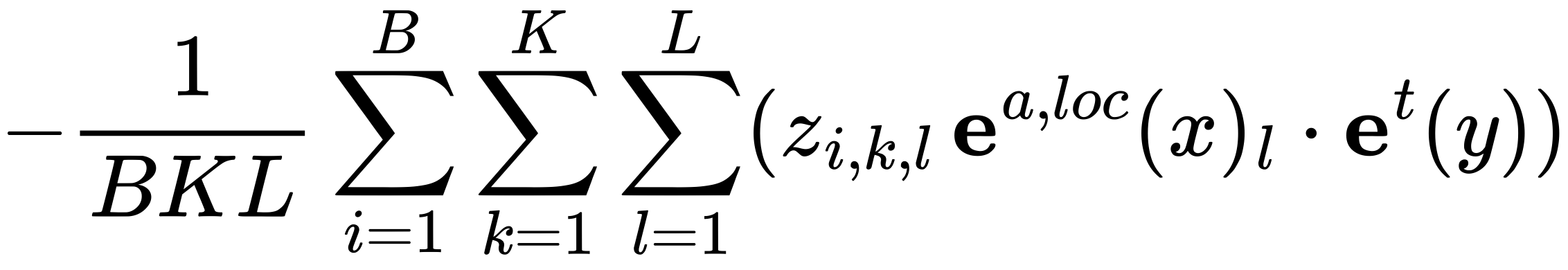
For the experiments involving smaller batch sizes, we trained the models for additional steps to ensure they were exposed to approximately the same number of training samples as the baseline (batch size 512).
The model trained without sigmoid loss encountered instability during training, with gradients becoming infinite around step 20k. As a result, training was terminated early. This highlights the importance of the sigmoid loss for stable optimization. We report its performance based on the checkpoint at step 20k.
Experiment Results
The results of these ablation studies are shown in the figures below. Models trained with batch sizes of 256 and 128 achieved similar SED performance to the baseline, with only minor performance degradation at smaller sizes—likely due to fewer negative samples per batch. In contrast, the model trained without sigmoid loss failed to converge and exhibited significantly worse performance, underscoring the crucial role of the sigmoid objective in enabling effective frame-level training.
Tables
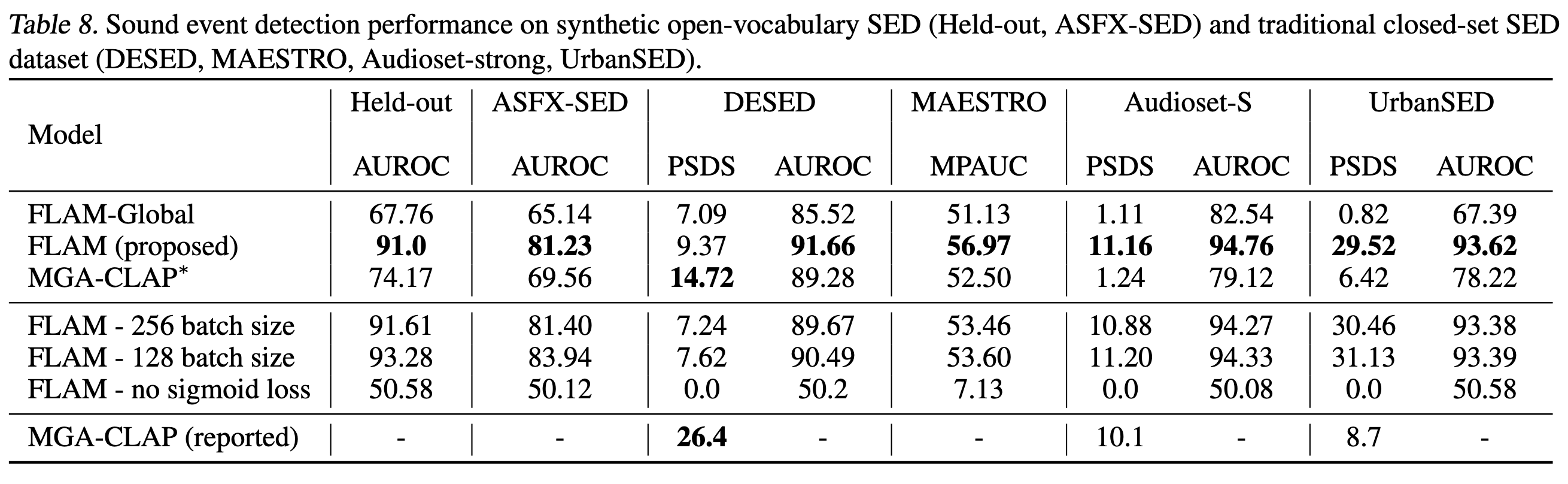
FLAM Compared with Current State-of-the-Art

[1] Schmid, F., Primus, P., Morocutti, T., Greif, J., & Widmer, G. (2024). Improving audio spectrogram transformers for sound event detection through multi-stage training. arXiv preprint arXiv:2408.00791.
[2] Li, X., Shao, N., & Li, X. (2024). Self-supervised audio teacher-student transformer for both clip-level and frame-level tasks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32, 1336-1351.
[3] Zhang, Y., & Togneri, R. (2025). Pseudo Strong Labels from Frame-Level Predictions for Weakly Supervised Sound Event Detection. arXiv preprint arXiv:2501.03740.
Note: The model in [3] is not a strong-performing model, but this is the only paper we found that reports results on the UrbanSED dataset.